
Overview
We set two goals for overProof:
| 1 | To reduce the false-negatives (the misses) on a corpus search caused by OCR errors by at least 50%, and to reduce the false-positives (incorrectly returned results) by the same amount.Rationale
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | To improve the readability and reusability of OCR'ed text by removing at least 60% of OCR errors.Rationale
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



Datasets
Evaluation requires a large amount of "raw" and "ground truth" text from content of significant interest to humans.
Compiling typical and accurate "raw" and "ground truth" text is very difficult, as explained in detail below. To be "typical", the OCR text should have been produced from sources which will be used by the target audience. Results obtained by evaluating effectiveness on synthetic material produced by, for example, printing and scanning known "ground truth" text cannot be extrapolated to real world use. Our main interest is to evaluate overProof on 19th and 20th century newspapers, often digitised from degraded copies or old microfilm, so it is that material we must use for testing.
Similarly, it is important to evaluate effectiveness on text produced using a particular OCR implementation. Owing to the widespread use of ABBYY's FineReader, we chose an evaluation based on text generated by FineReaderWe have formally evaluated overProof on 3 datasets:
- Dataset 1 - Sydney Morning Herald mostly corrected medium length articles, 1842-1954. A large amount of text, but poor quality "ground truth"
- Dataset 2 - Sydney Morning Herald completely corrected medium length articles, 1842-1954. A randomly selected subset of Dataset 1 containing 159 articles manually corrected to "ground truth".
- Dataset 3 - Article text from the Library of Congress Chronicling Americanewspaper archive. A randomly selected sample from 5 U.S. newspapers manually corrected to "ground truth".
Methodology
Each dataset consists of newspaper articles. We have 3 versions of the text for each article:
- The text as OCR'ed
- The "ground truth" version of this text, produced by human correction of the OCR text
- The text corrected by overProof operating on the OCR text
We perform 3 measurements on each dataset:
- Recall improvement. Finding an article in a search engine relies on the indexing of the correct article text. This measurement calculates the reduction in search misses achieved after article text correction. It does this by comparing the number of unique "ground-truth" words found amongst the OCR text with the number found amongst the corrected text.
- Readability improvement. The readability of article text is determined by the accuracy of the digitised text. This measurement calculates the reduction in the number of erroneous words after article correction. Note that whereas the recall improvement measurement requires that only one of possibly several occurrences of a "ground truth" word be accurate, this measurement considers how many occurrences are correct.
- Weighted-recall improvement. Similar to the first measurement, but also weights the importance of words based on their entropy. So, for example, a correction of common words such as the and one is much less valuable than a correction of a rare word which is more discriminating in selecting just a small number of articles. Exactly what rare words are varies from dataset to dataset. For example, in the SMH datasets, Sydney is a common, non-discriminating word, but a relatively rare word in the U.S. newspapers dataset. Also, despite being relatively common, Sydney may be a valuable discriminator when combined with other search terms, for example, Sydney Cricket Ground.
Testing is performed as follows:
- Words are extracted from each version by splitting the text on white space. Leading and trailing punctuation are discarded. Single character words, words starting with currency symbol or containing numbers and other non-alphabetic characters (other than hyphen and apostrophe) are discarded. Hyphenated words are changed to their non-hyphenated form. Words are changed to their lower-case form.
- The entropy of "ground truth" words is calculated for the dataset.
- A set of unique words appearing in each version (original OCR, ground truth and corrected) is created, recording the number of times they appear in each version
- Words from the ground truth version are checked for appearance in the original OCR and corrected version. For the recall measurement, only presence or absence is noted. For the readability/word-correction measurement, the number of occurrences of words is counted. For the weighted-recall measurement, the log of the occurrence count of the word in the article is multiplied by the word document entropy.
Dataset 1 - Sydney Morning Herald mostly corrected medium length articles, 1842-1954
Background to the National Library of Australia's Trove newspaper archive
The NLA's Trove Digitised newspapers site contains over 10 million OCR'ed newspaper pages. Each page is zoned into its component articles. The public can correct the OCR, and as of December 2013, over 100M column-lines of text have been corrected. Although this seems a vast amount, only a few % of articles have any corrections, and a tiny percentage of articles have been fully corrected.
The NLA newspapers site search identifies articles with at least one correction, and for each article, it is possible to retrieve both the most recent version of the text (incorporating all corrections made to-date) and a complete history of corrected line pairs (showing the text before and after the correction and the date of the correction). Hence, by obtaining a copy of the current version of the text and then by backing-out corrections in reverse-date order on that copy, it is possible to recreate the original text, as OCR'ed.
Extracting original OCR and corrected content from Trove
We scraped search results of all medium-length (between 101 and 1000 words in length) news articles from the Sydney Morning Herald by year, for each year content was available, from 1842 until 1954, and then for each article with at least one correction, we crawled the corrections and the current text. If the number of correction lines was 85% or more of the total number of lines in the article, we considered the article as 'fully corrected'. This does not mean that for these documents that at least 85% of lines have been corrected, as the same line is sometimes corrected more than once. However, it does mean that humans have spent considerable time correcting the article. A subsequent test, Dataset 2 was more rigourous in selecting 'perfectly' corrected articles, but was necessarily based on a smaller sample of articles.
We chose the Sydney Morning Herald title because it is one of the longest-running titles in the NLA corpus, it is accessed more than any other title on the NLA web site, and its presentation, image-quality and content are typical of other titles in the corpus. We chose news articles (rather than family notices, detailed lists and results, or advertising) because they form the majority of all articles: 4.5M from a total of 5.8M. We chose medium-length articles because very few long articles have extensive corrections and because medium-length articles form a majority of all news articles (2.6M from a total of 4.5M).
Of the 2.6M articles examined, 169K had at least one correction, and 30,301 met the 85% correction lines criteria, and hence were added to this dataset.
Per-year files containing the line-by-line original OCR and human correction line pairs for these 30,301 articles are available here. Each file contains multiple articles. Each article starts with a header line identified as starting with *$*OVERPROOF*$* , and followed by original OCR text and current version text pairs, for example, the 1842 file starts like this:
*$*OVERPROOF*$* 12409236 year 1842 type Article title The Sydney Morn lUHSr.1 rë10.vl TUS IMXHRÃÂOR.||@@||NEWS FROM THE INTERIOR. (From our various Correspondents.)||@@||(From our various Correspondents.) NEWCASTLE.||@@||NEWCASTLE. A vnnY melancholy accident, occa ioncd by||@@||A very melancholy accident, occasioned by the incautious use of fim-arini, ocuiirrcd here||@@||the incautious use of fire-arms, occurred here on Saturday last, to one ot the privates of the||@@||on Saturday last, to one of the privates of the
The NLA newspaper article id follows the header line marker. In this case, it is 12409236, and can be used to view the article on the NLA web site, retrieve just the article text, and retrieve the full line-by-line correction details.
Article line pairs consist of the original OCR text and the current version at the time of the crawl (which may or may not have been corrected), separated by the six characters: ||@@||
Limitations of treating extensively corrected articles as "ground truth"
It soon became apparent that is it not possible to treat even extensively corrected versions of articles as "ground truth". Amongst the problems:
- Not all lines with errors have been corrected. Even with the 85% criteria, correctors often leave a heading or final paragraph uncorrected, or just miss 'obvious' errors in a line and don't correct the line.
- Human corrected lines inevitably contain uncorrected errors. For example, Thc, and in general, e erroneously OCR'ed as c are frequently not spotted by humans.
- Line boundaries are changed. Some correctors occasionally move text across line boundaries for no apparent reason. Sometimes this is minor, such as combining both parts of a hyphenated word on its starting line and removing the hyphen. Other times, it is less predictable, for example, see the extensive realignment performed on this article on 7 Oct 2010.
- Words are changed. Quite commonly names formed as, for example M'Donald are corrected as McDonald. Occasionally, newspaper typos are corrected, and words are deliberately changed rather than corrected.
- Content is added. Quite commonly, the OCR and zoning process misses text at the start or end of line, entire lines, or a paragraph, typically at the end of an article. An example in this article occurs in the corrected line starting E. A. Tyler - the two following lines were not OCR'ed, but were appended on to this line by the text corrector.
Such issues create many problems when attempting to evaluate the performance of an OCR correction process, both because the human "ground truth" is not totally truthy, and because the raw OCR is totally missing some content that appears in the "ground truth".
As a consequence, we noticed overProof consistently generating valid corrections which had not been made in the "ground truth", and also new text which had been added by human corrections to the "ground truth" which had no source raw OCR.
Because of the poor quality of the "ground truth" in Dataset 1, we abandoned attempts to produce a meaningful evaluation of correction performance. However, when we ran the evaluation described below on the other datasets on this dataset, we found a reduction in recall misses of about 54% and raw word error rate reduction of about 62%.
Whilst selecting articles with a large number of corrections helped to avoid partially corrected articles, it did bias the sample towards articles with poor-quality OCR, and hence reduce how representative this sample is of the corpus. We addressed this concern with Dataset 2.
Dataset 2 - Sydney Morning Herald completely corrected medium length articles, 1842-1954
Given the significant numbers of human correction errors in Dataset1, we selected a random subset of articles and examine and correct them to a "ground truth" standard. From the 169K SMH medium-length newspaper articles with at least one correction, we selected all articles whose NLA assigned article id ended in 3 zeros. There were 159 articles selected. We chose to sample all articles with at least one correction, rather than articles with 85% correction lines to avoid biasing the sample towards those articles with lots of errors.
Results
Evaluating the 159 articles containing 47,375 words gave the following results:
| Uncorrected text | Corrected text | |
|---|---|---|
| Recall | 83.8% | 94.7% |
| False positives | 26.7% | 8.7% |
| Raw Error Rate | 18.5% | 5.0% |
| Weighted Error Rate | 16.2% | 5.9% |
The calculation of recall miss and false positive reduction gives the following results:
| Recall misses reduction | 67.1% |
| Recall false positive reduction | 67.3% |
| Raw word error reduction | 73.2% |
| Weighted word error reduction | 63.6% |
That is, after correction, the number of documents missed on a keyword search is reduced by 67.1%, the number of false positives is reduced by 67.3%, and the raw number of error words is reduced by 73.2%.
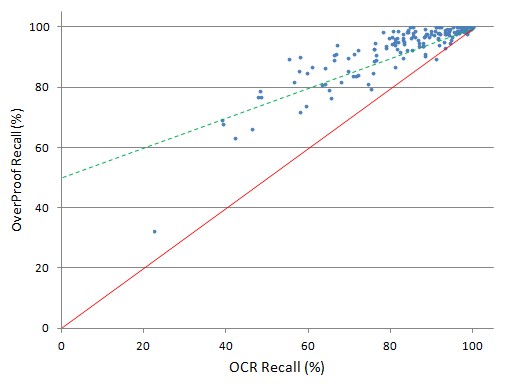
Recall (%) of corrected and uncorrected text for each of the 159 articles sampled.
The solid red line divides those articles for which recall was improved (above the line) from those for which recall was degraded (below the line).
The green dotted line represents a 50% reduction in recall misses.
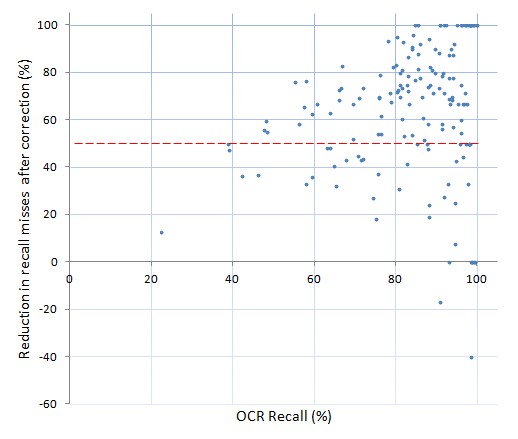
Reduction in recall misses (%) plotted against the recall (%) of the uncorrected text
The red dotted line represents a 50% reduction in recall misses.
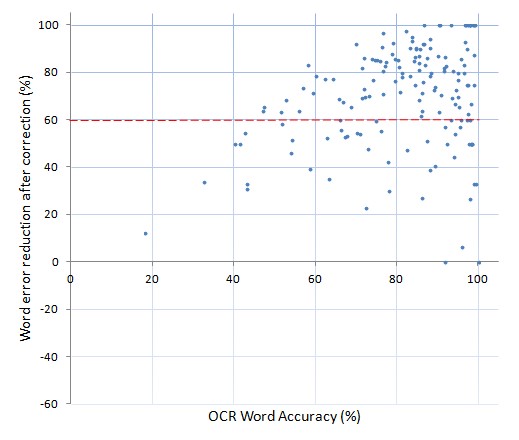
Word error reduction after correction (%) plotted against the word accuracy of the uncorrected text (%).
The red dotted line represents a 60% reduction in word errors.
Dataset 3 - Library of Congress Chronicling America completely corrected medium length articles, 1871-1921
Although the SMH is representative of Australian articles, it is not necessarily representative of titles from other countries in content nor in print quality (the presses used by Colonial Australian newspapers were often second-hand discards from Britain).Hence we randomly selected articles from several issues and pages from 5 titles within the Library of Congress data archive. We selected issues from the randomly chosen batches nearest the winter and summer solstice, if available, otherwise from the start and end of the run.We selected 49 news-type articles from the first and/or second pages, containing approximately 18,100 words and hand-corrected each article with reference to the PDF image of the corresponding page.
The titles and dates sampled:
- THE CAIRO DAILY BULLETIN (ILLINOIS) 21 June 1871 page 2, 21 December 1871 page 2, 5 April 1872 page 2
- THE MOHAVE COUNTY MINER 18 June 1887 page 1, 23 June 1894 page 1, 17 June 1899 page 1,20 June 1903 page 1
- THE INDEPENDENT (HONOLULU) 25 June 1895 page 1, , 21 July 1896 page 1, page 2, 21 June 1897 page 1, 21 June 1898 page 1
- THE SAN FRANCISCO CALL 1 January 1900 page 1, 1 February 1900 page 1, 1 March 1900 page 1, 1 April 1900 page 1 (Magazine section)
- THE WASHINGTON TIMES 21 June 1921 page 1
Results
Evaluating the 49 articles containing 18,106 words gave the following results:
| Uncorrected text | Corrected text | |
|---|---|---|
| Recall | 84.0% | 93.6% |
| False positives | 23.6% | 8.5% |
| Raw Error Rate | 19.1% | 5.9% |
| Weighted Error Rate | 16.0% | 7.0% |
The calculation of recall miss, false positive, raw and weighted error reduction gives the following results:
| Recall misses reduction | 59.9% |
| Recall false positive reduction | 64.2% |
| Raw word error reduction | 69.0% |
| Weighted word error reduction | 56.2% |
That is, after correction, the number of documents missed on a keyword search is reduced by 59.9%, the number of false positives is reduced by 64.2%, and the raw number of error words is reduced by 69.0%.

Recall (%) of corrected and uncorrected text for each of the 49 articles sampled.
The solid red line divides those articles for which recall was improved (above the line) from those for which recall was degraded (below the line).
The green dotted line represents a 50% reduction in recall misses.

Reduction in recall misses (%) plotted against the recall (%) of the uncorrected text.
The red dotted line represents a 50% reduction in recall misses.

Word error reduction after correction (%) plotted against the word accuracy of the uncorrected text (%).
The red dotted line represents a 60% reduction in word errors.