
so that you can search, read and reuse your text more effectively
OCR engines are in the business of character recognition.
OverProof is in the business of word recognition.
On a typical scanned newspaper corpus, overProof will reduce the number of articles missed by a keyword search due to OCR errors by over 50%.
More..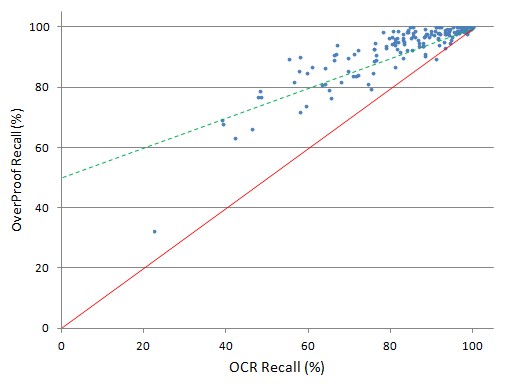
The problem overProof solves
OCR engines attempt a difficult task: converting colour and contrast variations on an image into text. Their job is made harder by poor original and image quality: poor and aged paper and inks, poor print quality, bleed-through, page-skew and less than optimal image-capture are common yet impossible or expensive to address constraints.
OCR engines need to balance processing speed and cost against accuracy, and they don't come equipped with the massive statistical and contextual language models required to generate the best possible output.
Text searching is the primary way users interact with a large text corpus. Without high OCR accuracy, searchers will miss much relevant material and confidence in the corpus will suffer.
A large corpus typically represents an investment of many millions of dollars; it is vital to maximize the returns on that investment by ensuring the quality of the text is as good as it can be.
On a typical scanned newspaper corpus, overProof will reduce the number of documents missed on a keyword search due to OCR errors by over 50%.
A large digitised corpus represents an investment of millions of dollars. OverProof economically and significantly improves the searchability and readability of its text and hence the utility of the corpus.
More..Full text databases are being 'mined' to explore hitherto undiscoverable relationships. However the effectiveness of such processing is limited by the inconsistent quality of the OCR'ed text.
For example, this Google search returns over 1000 documents from Australian educational institutions with a particular OCR error: the interpreted as tlie, whilst this search returns documents containing just one variation amongst thousands of Sydney.
Humans will always be needed to correct the most difficult errors and content from the poorest scans, but overProof can automatically and economically fix the majority of errors, freeing humans to target the most difficult cases.
We built the original 'human' text correction system used by the National Library of Australia's digitised newspapers system. It has been very successful: over 100 million lines of text have been corrected by human volunteers.
However, the scope of the task is daunting, and even these dedicated volunteers have corrected only a tiny proportion of errors, and that proportion is steadily falling (Trove crowdsourcing behaviour presentation Information Online 2013, by Paul Hagon, see slides 47 - 55).
How you can use overProof to correct your OCR'ed text
You don't need to install software or manage hardware - just send OCR'ed text to your private queue on an overProof server and receive back the corrected text.
OverProof processes and returns content in ALTO, hOCR and plain-text formats. If you use other formats, just let us know.
Encrypted data transmission to and from the overProof servers is available.
For sensitive materials, content can be encrypted with your public and private keys and always stored as encrypted on the servers.
The overProof servers are located in one of Europe's largest and most respected data centres.
With the flexibility of a large server farm, overProof can provide rapid turnaround for large volumes of text. Throughput of tens of millions of words per day is standard, and can be scaled to meet your requirements.
Almost real-time turnaround (1 second per thousand words) can be provided if required.
Pricing is dependent on volume, but costs as little as 5 cents per 10,000 words. That's about 30 pages of a typical novel, or a very dense broadsheet newspaper page without illustrations.
There's no need to signup, just paste your own text into our online demo, and see for yourself, or browse some before and after examples.
If you'd like to try uploading files, just contact us for a free trial account.
A description of how overProof's performance has been evaluated on real OCR text is available here.
How overProof works
| 1 | OCR Error ModelsOCR text contains errors characteristic of the process. For example
There are dozens of frequently-seen errors for every character, character bi-gram (pair) and character tri-gram. By analysing gigabytes of OCR'ed text, OverProof has learnt the error probabilities for hundreds of thousands of character sequences. OverProof also uses a visual representation model to evaluate the likelihood of various OCR errors, and incorporates a vast corpus of human word and phrase correction of OCR text to supplement the simpler character correction model with some language context. |
| 2 | Language ModelThe OCR error models typically yield hundreds of possible character combinations for each OCR word, and because split and joined words are common OCR errors, tens of thousands of possible 'original' texts could be derived with reasonable probability from even a short sequence of OCR'ed words. OverProof's language model has been trained on hundreds of gigabytes of text to evaluate the probability of each possible word combination. For example
Accurate correction without a broad and deep language model is impractical. |
| 3 | Language ContextWhilst an extensive language model provides excellent 'on average' guidance during correction, each block of text occurs in a local language context. Hence the language model for an newspaper article discussing contemporary Australian politics from 1895 will be very different from the language model of a romance fiction novel from 1962. OverProof constructs a language context for each block of text based on the known words it identifies within that text, and uses this context to dynamically adjust the language model. |
| 4 | Iterative correctionOCR correction requires solving an immense combinatorial problem. Exhaustive search is not a feasible approach. OverProof performs up to 15 'passes' over uncorrected text, identifying 'islands' of likely good and bad text using a variety of algorithms to generate suggestions both very rapidly and at great depth, refining the contextual probabilities of each correction at each step. |
Who are we?
We're an Australian-based software house. Over the past 30 years we've developed systems used by large commercial and government organisations around the world.
Recently we've been deeply involved with the design and implementation of the immensely popular and award-winning Newspaper digitisation and Trove discovery systems at the National Library of Australia.
We've been designing and implementing large-scale text searching systems since the 1980's. We've also have a long and deep experience with large mathematical models of the type used by overProof which we can use to assist you with other text corpus processing such as quality analysis, vocabulary extraction, named entity extraction, preliminary search term extraction, sentiment analysis and visualisation.
You can find out more about us here.