Posted by Mahendra Mahey on behalf of Kent Fitch, Project Computing Pty Ltd.
My company was recently contacted by Mahendra Mahey, Project Manager of the BL Labs. Mahendra was aware of text correction tests we'd performed for Amelia Joulain-Jay's analysis of Optical Character Recognition (OCR) errors in Victorian newspapers, based on the BL's digitised newspaper archive, and he and his colleague Ben O'Steen were now working with researcher Hannah-Rose Murray, mining the newspaper archive for her project, "Black Abolitionist Performances and their Presence in Britain".
Containing the digitised images and OCR'ed text of over 14 million pages, the British Newspaper Archive is an incredible resource for researchers and the general public. More than just news articles (the "first draft of history"), the family notices, advertisements and discussions available in the archive help us research and understand the issues, attitudes, customs and habits defining the lives of our ancestors.
The importance of effective text searching grows with the size of the archive: needles in the haystack must be found before they can be examined. But searching relies on OCR quality, and OCR is error-prone, particularly for old newspapers: fonts are small and the original pages are frequently damaged, suffer from ink smudges, bleed-through and imperfect digitisation.
Just one example based on our experience with the similarly sized newspaper archive digitised by the National Library of Australia (NLA): many thousands of different (and erroneous) OCR variations on the name of the town Kalgoorlie appear in over 300,000 articles which consequently cannot be found on a search for that word. This is a "long-tail" problem: many of the errors appear many times due to characteristic single mistakes in the OCR process (Ealgoorlie, Kalgoorlle, Kalgoorlio, Kaigoorlie, Kalgoorlic, Kalgoorhe) but many more contain multiple mistakes (Ealsoorlic, Kaigcorhe), less obvious errors (fvalgooriie, ^ALGOORLIE, fealgoorrie, Kalssorlie, KaJsoorlic, all occurring in the same article) and just bizarre errors (Ka1go?el, Ivalgoculte, Xálgojrhe).
Hence, about 20% of the Kalgoorlie needles in NLA's "haystack" are very hard to find, and each word added to a search, such as Kalgoorlie Municipal Council, increases the percentage of missed results at a near-exponential rate.
Hannah-Rose identified similar problems in her original blog post and in her recent update. See cites the example of Frederick Douglass, a fugitive slave from America addressing public meetings in Britain in 1847, and the importance of being able to search on his name, and associated words such as "American" and "slavery".
Mahendra sent us almost 12 million words of OCR'ed text in 970 files from a selection of 19th century newspaper titles from the BL corpus for us to correct using the overProof post-OCR correction software. Of these files, 37 were from Welsh titles we excluded because overProof has not yet been trained to process Welsh, leaving 933 files to process. As a typical 19th century broadsheet page contains around 10,000 words, this sample is the equivalent of about 12,000 pages, that is, less than 0.01% of the BL's digitised newspaper corpus.
Even in this relatively small sample, overProof found and corrected over 100 OCR-variations of Frederick, such as: Prederick (5 occurrences) Firederick (3 occurrences) rederick (2) Froderick (2) Fredericle (2) Fiederick (2) and dozens of "singletons" such as tFrederick PFedericl FWRDERICK FRIEDERIICKC FREDnERsICK FREDEXICK F~rederiek F2rederic Fi-deick Ereuerick and 1:REDERICK.
Even a relatively rare word such as Douglass had several OCR variations: Douglars Dotuglass Dottglas,% D)otglass and Donglass.
Another less-common name, Grimshaw, appears correctly in the raw OCR five times, and once as GRIMSHAW. OverProof identified another fifteen variations of Grimshaw, all except one of which (Grimehaw) occurred just once in the 12 million word test corpus: Grmhaw Grinshaw Grineshaw GrInahaw Grimshawv Grimohaw Grimehw Grimashaw Grimahaw Grimabaw GRIM8HAW Gricashaw frimnhaw and fiBIMS1AW (you have to squint quite hard to see that one!)
Clearly, these errors are very significant to anyone searching for Grimshaw, but they barely scratch the surface of how that name can be mis-OCR'ed. They don't for example, include the most common errors we found in another large English language newspaper corpus: Gnmshaw Grlmshaw Crimshaw.
There are almost 300 erroneous versions of American in the sample: Amnerican (14) Anmerican (7) Amierican (6) Anerican (5) Aimerican (4) Amuerican (3) Arnerican (2) Anserican(2) Americall (2) Ainerican (2) and over 250 singletons including: mmerivcm LAmericvni MEl{ICAN *mcii!to .kmericar IIAmerIcan Anie'rican AMERIO&N AMiEBICA2I Amer~icani A)MERICAN Amer~ican Amer/con AIIERICAX AIUTRICAN Acierican A5MERICAN A4mef.ican A111ricanl and 4ir~ie-n.
Some of the over 40 variations of slavery corrected were: SLAVEIRY (2) slarery (2) and tslavery Sltverv elartsry dslavery and Si,&vERY.
The "long tail" nature of these errors means that a simple table of error corrections is not viable. If we took another sample of 12 million words from the archive, we'd see the occurrences of the common errors double, some of the singletons would reappear, but the vast majority of errors would not have been seen before: the frustrating reality is that there are hundreds of thousands of quite plausible mis-OCRs of the word American.
OverProof tackles this problem with several approaches:
The best way to measure the improvement made by the correction process is to compare the OCR'ed text and the automatically corrected text with a perfect correction made by a human (known as the "ground truth"). Unfortunately, hand-correcting text is both time consuming and itself quite error prone. Hannah-Rose kindly provided five corrected segments, but these amounted to 3100 words, or less than 0.03% of the sample. To assess the bulk of the corpus, we fell-back to a common technique of using a spell-checker augmented with proper nouns to measure the number of unknown words in the original and corrected text.
In this case, we used "Aspell", and plotted for all 933 documents, the percentage of words not in Aspell's extended dictionary before and after correction. This measure has known inaccuracies: it does not properly count good OCR words corrupted by the correction process, erroneous but nonetheless valid-dictionary-word corrections, and correct words (both OCR and corrected) not in the spell-checker's dictionaries (frequently these are proper nouns). However, previous experience suggests it is a reliable if rough measure of effectiveness.
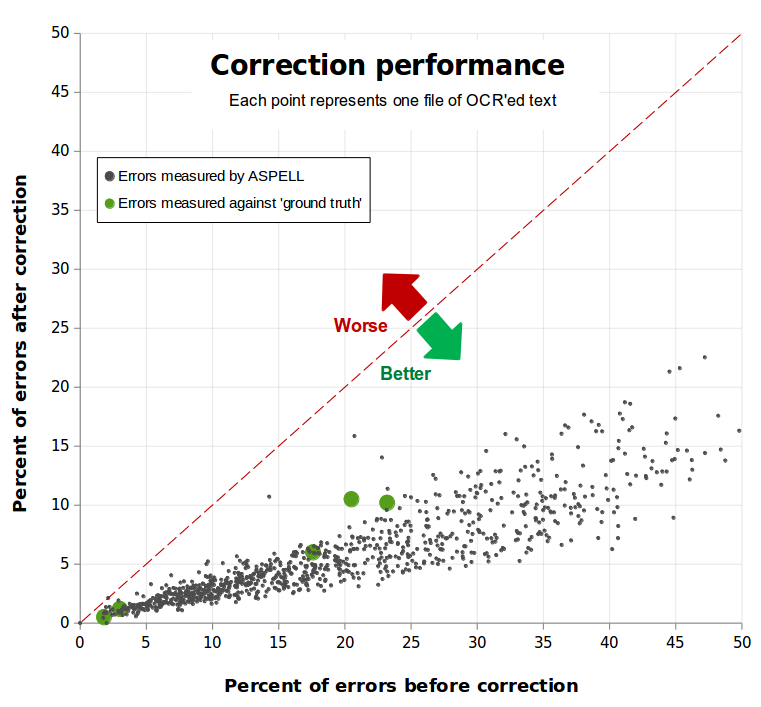
Each grey dot in the first graph below represents a file supplied by Mahendra. For each file, the horizontal axis shows the percentage of words not in Aspell's dictionary before correction, and the vertical axis shows the same percentage after correction. The gross words in error falls from 19.6% before correction to 5.7% after correction. That is, the overProof correction process has removed about 70% of the errors.
Hannah-Rose's 5 small human-corrected samples are show as green dots. These are not only smaller than the other files, but their raw error rate is much lower at 13.3%. OverProof was measured as reducing this to 5.4%, a removal of almost 60% of errors.
The red dotted-line indicates the correction "break-even" point: the further under the line, the better the quality of the document after correction.
Another way of visualising correction performance is to plot the number of files for various error rate ranges. In the graph below, the grey line shows distribution of files across error rates before correction and the green line after correction.

We had previously evaluated overProof's performance on Australian and US newspapers, so we were keen to see if those results could be anticipated on the large British newspapers corpus. It was a great pleasure working on this evaluation with Mahendra, Hannah-Rose and Ben, and my colleague, John Evershed and I thank them and the British Library for this opportunity. Our work continues to improve overProof's correction accuracy so that more needles in more haystacks can be found and used to enrich our understanding of the past.